
Vous payez surement un accès à l’API de Gemini, OpenAI ou Mistral. Mais savez-vous comment fonctionne la facturation ? On parle souvent de prix par million de tokens, d’input et d’output, mais comment ça marche exactement ? Comment fonctionne la facturation lorsque l'on utilise ces services d'IA ?
Comprendre les "tokens"
Déjà pour commencer, il faut déjà comprendre comment une IA générative fonctionne. Lorsque vous écrivez “Salut, comment ça va” en prompt de votre IA favorite, le modèle ne lit pas mot par mot votre demande. Les LLMs utilisent des tokens. Voyez ceci comme un gros dico contenant des mots ou des groupes de mots associés a un nombre unique. Ainsi, l’IA apprend a reconstruire une suite de nombre, plutôt que du texte brut.
Dans les modèles récent ce n'est plus vraiment un "dico brut nombre à mot"; on parle maintenant d’embed (qui représente des vecteurs dans un espace de dimension R). Mais le principe reste le même.
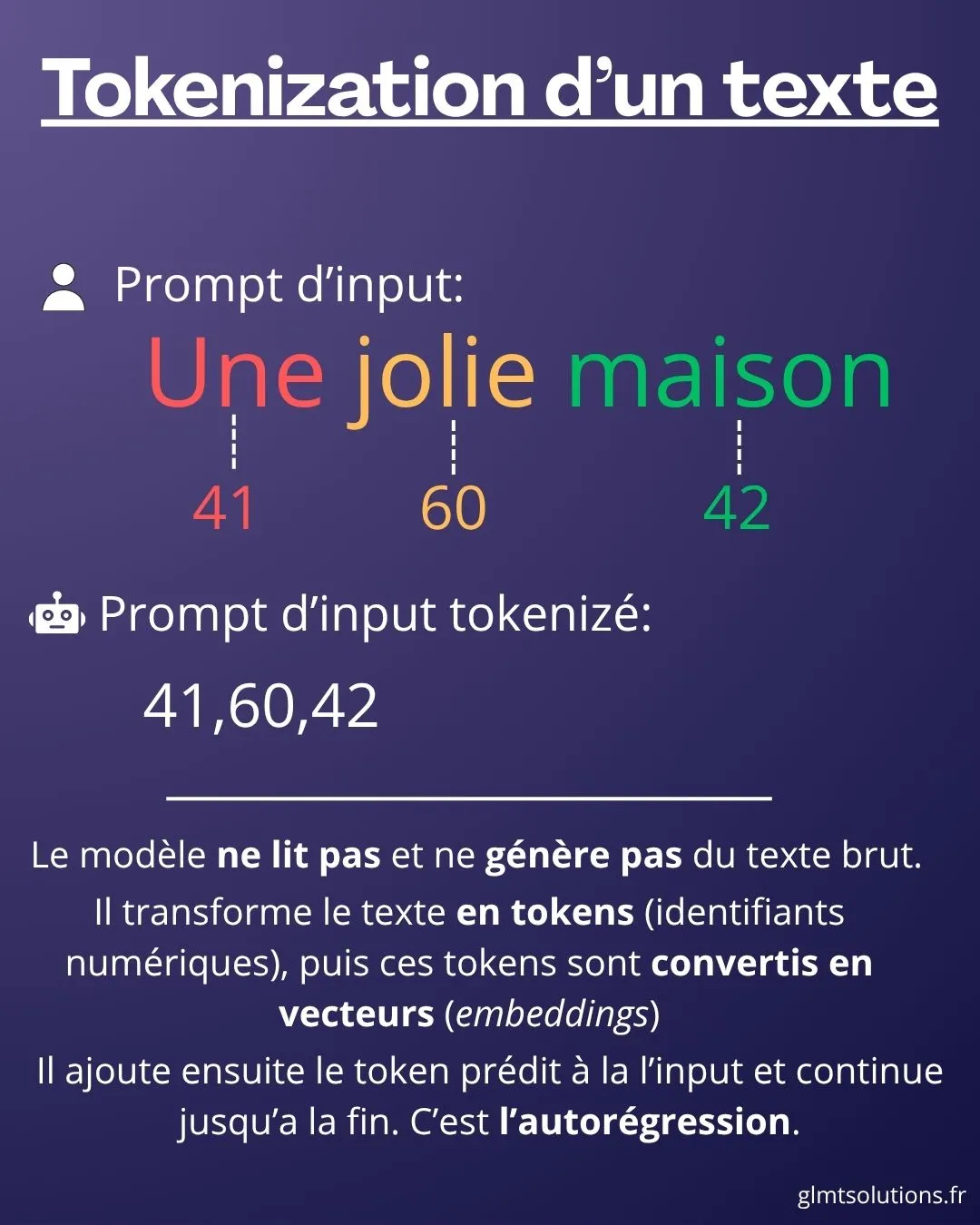
Dans cet exemple très simpliste, le modèle aura donc 3 tokens en entrée (ici il n'y a pas de prompt système, pas de prompt admin, pas de pré-prompt, seulement un prompt de l'utilisateur). A noter, un token n'est pas forcément un mot, mais ça peut être un groupe de mot, ou de la ponctuation voire même une partie de mot ou un symbole.
Le coût du token d'input
En général, les tokens d'input ne sont pas la partie la plus coûteuse du processus car le modèle ne passe qu’une seule fois sur le texte. On estime d'ailleurs qu'en général, la tokensization du texte d'input coûte entre 2-3 voir 4 fois moins cher que pendant l'inférence (processus de génération de texte).
Le piège des tokens de sortie
Pour comprendre pourquoi la génération du texte peut couter vraiment cher, il faut d'abord comprendre comment un modèle procède pour générer du texte. Si l'on prend un modèle très simple - sans raisonnement et en prenant le token ayant la plus grosse probabilité - le nombre de token de sortie dépend du nombre de tokens que l'IA va générer, du texte d'entrée et du nombre d'itérations pendant l'autorégression.
Voici un exemple: vous demandez “J*’habite dans une*”. Si je demande une réponse de 4 tokens, l’IA va techniquement relancer les calculs 4 fois en reprenant tous les tokens et en ajoutant un token généré, c’est pour cela que la génération du texte est assez coûteux.
À chaque étape :
- Il prend tout le texte (le prompt + ce qu’il a déjà généré)
- Il calcule les probabilités
- Il ajoute un nouveau token
Et il recommence jusqu'a atteindre la limite de tokens max ou alors un tag de fin.
- J’habite dans une MAISON
- J’habite dans une maison JAUNE
- J’habite dans une maison jaune AVEC UN
- J’habite dans une maison jaune avec un CHAT …
Vous comprenez ainsi pourquoi il est impossible de prédire à l'avance combien va couter un prompt. Surtout que de nos jours, les modèles utilisent des tools, des raisonnements, des algorithmes pour trouver le meilleur token qui ne se base pas sur "la probabilité la plus haute".
Comment ne pas exploser le budget ?
Il y a en réalité deux points sur lesquelles vous pouvez jouer pour limiter les coûts tout en ayant de bons résultats.
Utilisez un modèle adapté
Les coûts sont souvent exprimés en euros par millions de tokens généré. Certains modèles ont des capacités et des raisonnements qui font que le prix d'utilisation d'un modèle à l'autre peut être de x10.
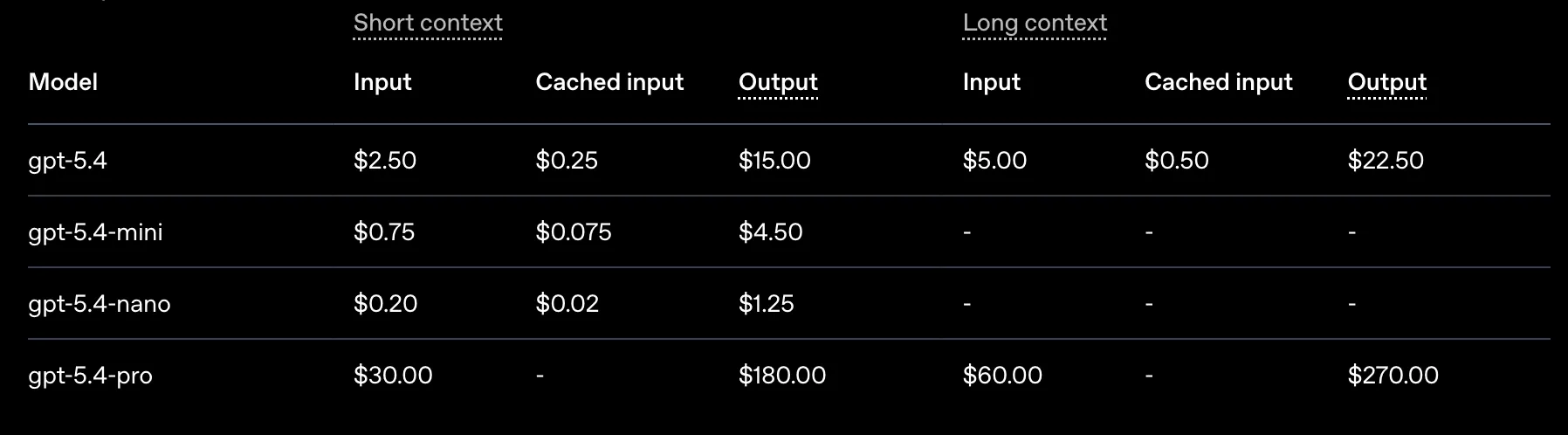
Prix pratiqués par OpenAI le 4/04/2026. Le prix par million de token varie énormément, surtout avec les modèles "pro". Disponible ici.
Ajoutez une limite maximale de tokens
L'autre axe sur lequel vous pouvez jouer c'est spécifier une limite maximale de token. Ce paramètre est spécifiable la plupart du temps dans la payload de la requête faite à l'API. Par exemple chez Mistral, vous pouvez ajouter max_tokens et spécifier un nombre maximal.